Abstract
Semantic retrieval based on Language Models embeddings is an established approach
for information retrieval from large scale textual corpora, however, its
application to digital humanities and specifically to ancient languages is still
limited. In this work we develop a tool for the semantic retrieval of Old Church
Slavonic and Church Slavonic texts and we present an investigation, carried out
by experts in Slavic Philology and Slavic Orthodoxy, of the
Nicene-Constantinopolitan Creed in these languages.
The main contributions of
the work are two: (1) We describe the creation of a reference dataset for
semantic retrieval in (Old) Church Slavonic, addressing key challenges such as
the limited availability of digital corpora, fragmentation of sources, and
character encoding inconsistencies; (2) We develop a tool for semantic retrieval
in these languages.
By collecting feedbacks from the experts using the tool to
study the Creed we find that it is reliable in supporting semantic analysis of
the Creed and its major strengths are: (a) identifying expressions that are
semantically related to the query based on context; (b) providing access to
diachronic sources and enabling assessment of their impact on the translation
and transmission of texts, particularly the Creed, which conveys the core
principles of the Christian faith. The experts also identified some limitations,
which will serve as a basis for future work and further improvement,
particularly when querying texts from manuscript corpora. These issues highlight
the need to: (a) enrich the dataset with manuscript sources using OCR and HTR
techniques; (b) account for script variation and historical or regional
orthographic differences. Our findings highlight how the tool proposed provides
both a useful infrastructure for the study of (Old) Church Slavonic as well as a
proof of concept for the application of semantic based information retrieval in
ancient literature.
The tool is available on HORTUS, the ITSERR project website:
ITSERR - Prototyping
Lab
1. Introduction
The goal of this paper is to present a tool for the semantic analysis of texts in
Old Church Slavonic and Church Slavonic. The need for a tool capable of enabling semantic
analysis of texts in this historical language emerged within the framework of a collaborative
project that aims to apply Natural Language Processing (NLP) techniques to religious
texts in various languages, using the Nicene-Constantinopolitan Creed as a case study.
This research is part of a broader scholarly initiative dedicated to the 1700th Anniversary
of the Ecumenical Council of Nicaea
[1]
(325-2025).
The Creed is a doctrinal text agreed by bishops convened in council that conveys the
fundamental tenets of the Christian faith. As a text regularly recited in the liturgy
and quoted in catechesis it exerts a significant impact on the target culture. Accordingly,
its semantic implications, particularly the theological significance of linguistic
and terminological variation, are of primary relevance. As shown by Gezen’s analysis
of the Creed in
Istoriia slavianskogo perevoda Simvola very (published in 1884; second edition: 2015), the examination of manuscript evidence
reveals a wide range of textual variation, which changes according to the historical
period and the regional context. More specifically, Gezen’s study demonstrates not
only the multiplicity of these variations, but also makes it possible to classify
the Slavic translation of the Nicene-Constantinopolitan Creed into three distinct
editions. Among these, the second edition survives in two different redactions which,
according to the scholar, differ both in terms of text and script: one is written
in Glagolitic characters, the other in Cyrillic. Furthermore, variation is also attested
within the same redaction. This is the case, for example, with the third edition,
in which both adjectives истиннагѡ (
istinnago - true) and животворѧщаго (
zhivotvoriashchago - life-giving) appear in the eighth article ([
Napolitano 2025]), as will be discussed in greater detail in the following sections of this paper.
Building on Gezen’s analysis, it emerges that up to the seventeenth century three
different versions of the Creed could still be found in liturgical texts. This view
seems to be confirmed by the comparative analysis aimed at assessing their linguistic
and historical significance. Additional differences become evident when comparing,
for instance, pre-reform texts other than those used by Meyendorff, particularly those
originating from the Polish-Lithuanian Commonwealth, where Catholic influence was
more prominent.
The present study is study thus originates from the intent to investigate the Slavonic
translations of the Creed (Сѵмволъ вѣры Символ веры - Simvol very) and to explore
the impact of different geographic areas and historical phases on the language’s transmission.
A particularly important point of reference is the revision of the Creed undertaken
during the liturgical reform of Patriarch Nikon,
[2]
with a specific focus on assessing the role of the Greek liturgical tradition in the
implementation of these revisions.
Following a review of the relevant literature on NLP for Old Church Slavonic (OCS)
and Church Slavonic in paragraph 2, the paper discusses the creation of a reference
dataset for the semantic retrieval tool (paragraph 3). This phase is particularly
complex due to the extreme scarcity of resources available for this language, the
fragmentation of digitized texts across multiple unsystematized digital libraries,
and the persistent issues related to character standardization, especially the widespread
use of non-Unicode characters. The following paragraphs will present the methodology
adopted for the development of the tool for the semantic retrieval (paragraph 4),
not only from a technical perspective but also through the analysis of evaluation
forms completed by a selection of expert scholars (paragraph 5). This testing group
includes six researchers specializing in Slavic philology, many of whom are actively
involved in digital humanities projects related to OCS and Church Slavonic manuscripts.
Their feedback will serve to assess the perceived reliability of the tool’s output
with respect to the primary objective of analyzing the Nicene-Constantinopolitan Creed,
and to identify the strengths and limitations of this novel contribution to NLP applied
to (Old) Church Slavonic.
2. Advances in NLP for Old Church Slavonic: Methods, Resources, and Open Problems
Despite the growing effectiveness of transformer-based text representations developed
through large language models (LLMs), these techniques remain underdeveloped for historical
languages such as Old Church Slavonic (OCS) and Church Slavonic, especially due to
the lack of training data.
This scarcity of data has had a significant impact on the work conducted in the field
of this project. In addition, the focus will be on diachronic information, which is
of particular relevance for research on Old Church Slavonic and Church Slavonic.
The following pages will briefly present the most relevant projects and studies in
the field of Old Church Slavonic and Church Slavonic research, in order to outline
the context in which our tool has been developed. This overview also aims to highlight
the current limitations and future challenges that must be addressed to consolidate
LLMs in this field of study and to improve their results.
More generally, NLP for OCS and Church Slavonic continues to face severe constraints,
primarily due to the absence of annotated datasets sufficient for training robust
computational models. An additional obstacle stems from the limited number of historical
linguists capable of providing expert human evaluation of model performances, which
hinders rigorous qualitative assessment. This remains a critical bottleneck, despite
recent advances that have improved performance in low-resource NLP through transformer-based
architectures, including historical languages.
[3]To date, research efforts have primarily focused on two major historical Slavic varieties:
Old Church Slavonic in the strict sense, and Old East Slavic (which represents the
attested form used in English to refer to texts written in древнерусский - drevneruskii).
The Universal Dependencies framework
[4] and the Stanza toolkit
[5] have played pivotal roles in providing both annotated corpora and processing tools
for these languages.
Previous attempts to develop NLP resources for pre-modern Orthodox Slavic texts have
employed a variety of strategies. Rule-based approaches to morphological analysis
have been notably explored by [
Baranov et al. 2007] and by
#moldovan_etal who did this wily while at the Russian Academy of Sciences
[6] Alternatively, tagging methodology from Modern Russian has been proposed for developing
a new pipeline in this field.
[7]Current state-of-the-art approaches to automatic Part-of-Speech (PoS) tagging and
morphological analysis for OCS have achieved results comparable to those in modern
NLP applications. While many corpora offer either gold-standard dependency annotations
or morphological tagging, some, like the PROIEL Treebank for Old Church Slavonic,
[8]
provide both.
Addressing this gap is essential for advanced syntactic analysis of historical Slavic
texts. In the following, several projects that have implemented these techniques will
be discussed.
The BogoSlov project presents a hybrid computational framework for identifying biblical
quotations and allusions in OCS texts. The system addresses the challenge of detecting
intertextual references that range from verbatim citations to paraphrased allusions.
It combines 1) rule-based methods using string similarity and
longest common subsequence metrics with 2) semantic methods leveraging embeddings from SentenceTransformers
(Sentence-Bert or SBERT) and RoBERTa on corpora from the late antiquity and early
middle ages. These methods are integrated into a CTS URN
[9]
- based model
[10]
for referencing source texts (primarily the Psalter and Gospels in OCS) and linking
them to homiletic and hagiographic target texts such as Vita Constantini and Vita
Methodii. The framework includes a graphical annotation interface to support expert-in-the-loop
validation, visualization of alignments, and manual metadata enrichment. Designed
to be extensible to other historical languages such as Latin or Greek, the framework
integrates symbolic and neural approaches to support philologically sensitive annotation
at scale.
[11] In a related study,
[12] the authors propose a mixed-methods, quantitative-qualitative framework for analyzing
Church Slavonic texts, using a 16th-century East Slavic manuscript and a 1519 South
Slavic printed SluzhebnikSlužebnik. Transcriptions were generated using Transkribus
(HTR), followed by a quantitative analysis and traditional philological validation.
This hybrid approach revealed differences across regional varieties and between manuscript
and printed forms, showcasing the potential of NLP-philology synergies in historical
Slavic research. The project forms part of a broader investigation of Orthodox Slavic
linguistic varieties (15th - 18th centuries) at the University of Łódź, which uses
corpus methods and automatic handwriting recognition to study vernacular-Church Slavonic
interactions. The proposed processing workflow includes three components: 1) HTR post-editing
and ground truth creation; 2) sentence-level classification with transfer learning
models for temporal and regional attribution; 3) token-level annotation of linguistically
salient features. The pipeline was evaluated on both HTR-derived and manually corrected
corpora, with attention to systematic HTR errors, tool limitations, and accessibility
for non-technical scholars. This modular system enhances the state of the art in historical
Slavic NLP by integrating automatic correction, supervised classification, and fine-grained
annotation in a reproducible and user-adaptable framework.
[
Scherrer, Rabus, and Mocken n.d.] laid foundational groundwork with
New Developments in Tagging Pre-modern Orthodox Slavic Texts, comparing a statistical tagger (TnT)
[13], MarMoT,
[14] which is used in particular to address problems with large tagsets, such as full
morphological tagging, and a bi-LSTM character-level tagger (CLSTM) on annotated [
Eckhoff et al. 2018]; [
Eckhoff and Haug 2021].
Their findings show that modern tagging architectures can achieve accuracies up to
95–96% without orthographic normalization.
[15]
The study also explored cross-linguistic and cross-corpus transfer learning, demonstrating
that synthetic or dialectal resources do not reveal substantial performance improvements
over models trained on low resources historical languages. This underlines the importance
of high-quality annotated corpora and establishes morphosyntactic tagging as a reliable
foundation for future semantic modeling in premodern Slavic NLP.
Building on this foundation, more complex PoS tagging systems have been proposed.
One of the most advanced systems to date is described in [
Berdichevskii, Eckhoff, and Gavrilova 2016], which combines a statistical PoS tagger (TnT)
[16] with a rule-based tagging module and a series of pre-processing steps. This hybrid
model achieved an accuracy of 92.7% for part-of-speech tagging and 81.5% for morphological
features. While these results are encouraging, recent advances in statistical and
neural tagging models, as well as in normalization techniques, suggest that further
improvements are possible. Subsequent work has built upon BEG16’s framework using
the TOROT treebank, which has since been expanded, increasing both training data size
and test set diversity. Additional sources, such as the Old Church Slavonic portion
of the PROIEL corpus, have been included to broaden the linguistic basis of experimentation.
Beyond the original use of the TnT tagger, more experiments have incorporated MarMoT
and taggers based on deep neural networks. Both the PROIEL and TOROT datasets have
been converted to the Universal Dependencies format, allowing for standardized PoS,
morphological, and syntactic annotation: this is a key step for enabling cross-linguistic
comparisons and annotation projection. In terms of evaluation, the field has moved
beyond simple accuracy and Hamming distance. Micro-averaged F1-scores are being used
to provide more granular insight into tagging performance.
Regarding character normalization, earlier approaches focused on lowercasing and removal
of diacritics, ligatures, and orthographic variants. More recent experiments updated
normalization routines and also explored tagging on unnormalized data, a scenario
highly relevant for digital Paleoslavic studies. Efforts have been made to integrate
external resources, such as the unannotated PLDR corpus (parallel Old Russian-Modern
Russian) and the Modern Russian SynTagRus treebank in UD format, but these have not
yielded substantial gains in accuracy.
[17].
In parallel to these tagging efforts, the focus of research on OCS and Church Slavonic
has increasingly shifted toward approaches using words and sentence embeddings. SuchThese
approaches open for more novel downstream tasks such as text classification and embedding
evaluation, semantic similarity and semantic retrieval. This paradigm shift also raises
the issue of the representation’s quality automatically learned from historical language
data.
Whithin In this framework, a major bottleneck for these downstream tasks lies at the
tokenization stage. As [
Dorkin and Sirts 2024] highlight, standard tokenization tools are poorly suited to the linguistic properties
of Old Church Slavonic and Old East Slavic,. These languages, which frequently result
in high out-of-vocabulary rates and unrecognized characters. Therefore, the development
of custom tokenizers for specialized embedding models is essential for achieving meaningful
representations in this domain.
Benchmark datasets and pre-trained models fine-tuned for language-specific tasks are
notably sparse for historical Slavic languages. Embedding-based models, originally
designed for applications in contemporary languages, often fail to align with the
goals of diachronic linguistic research applied to historical languages. In fact,
the main objective of diachronic research pursued so far, is to uncover patterns and
mechanisms of orthographic and grammatical variation within the data, rather than
to facilitate semantic question answering for accessing document content. In contrast,
the focus of our study, as outlined in the following sections, is the development
of a tool designed to retrieve sentences semantically related to a specific input
query.
As [
Lendvai et al. 2025] emphasize, techniques such as embedding similarity and retrieval augmented generation,
a methodology originally developed by [
Lewis et al. 2020], perform well on modern languages but are ill-suited for capturing the phenomena
of interest in historical corpora. A further shortcoming of current approaches is
the limited attention to temporal and geographic variation within historical Slavic
corpora. This specific study also adopts an approach to diachronic linguistics, in
which the focus lies in tracing orthographic and grammatical evolution over time rather
than in fulfilling semantically-driven queries aimed at producing interpretative outcomes.
To address this issue the authors also propose a classifier,
[18]
using manuscript metadata to assign spatial-temporal attributes, by both copying time
and region at the sentence level. Building on this, [
Lendvai et al. 2025] assembled a diachronically and dialectally heterogeneous corpus including South
Slavic manuscripts from the 10th-11th centuries and East Slavic recensions from the
15th -17th centuries. This dataset enabled the exploration of linguistic influence
between traditions. The analytical framework combined string-based representations,
such as character n-grams and term frequency - inverse document frequency (TF-IDF)
[19]
, with computational similarity techniques, including sequence alignment, local string
matching, and k-nearest neighbor (kNN) search based on cosine distance. These were
systematically contrasted with neural methods using text embeddings derived from SBERT
and BERT. Candidate ranking in retrieval tasks was performed via cosine similarity,
providing a quantitative basis for evaluating both traditional and neural approaches
to modeling linguistic variation.
Semantic similarity, which assesses how similar two sentences are, based on vectorial
representations that encoded high-level meanings of the word, has become a major focus
of recent research, especially in low-resource language [
Deshpande et al. 2023].
Dense text retrieval with LLMs has emerged as a particularly promising avenue, though
still relatively new. In particular, for LLMs to create vectorial representations
of text that encode semantic meaning, they require training over large scale corpora,
notable examples of this approach are the works from [
Artetxe and Schwenk 2019] and [
Reimers and Gurevych 2019]. Adaptation of these architectures to historical languages, with their unique orthographic
variants and fragmentary documentation, remains an open and rapidly evolving research
challenge.
As discussed above, in the scope of historical language, orthographic normalization
must be approached with caution. Non-normalized forms often carry important information
about temporal or regional provenance. These features are essential for capturing
linguistic change and for understanding the sociocultural dynamics that underlie orthographic
and morphosyntactic variation. Also for this reason, Lendvai’s study of the
Vita of Paul and Juliana, a text with Church Slavonic and Old East Slavic versions, is a notable case study.
[20]
Here, sentences from the earlier recension were used as queries to retrieve aligned
content from the later version, preserving historical variation while testing retrieval
performance. The dataset for this experiment was created through meticulous manual
alignment at the word level. Crucial to this work was the identification of parallel
texts across different manuscript sources. This allows for reuse of metadata typically
absent or inconsistently annotated in the original documents.
The attribution of texts to specific times and places has also been explored in a
work by [
Lendvai et al. 2023], who purposely fine-tuned BERT models. Their corpus includes six manually transcribed
texts drawn from medieval manuscripts and early printed editions from Southern and
Eastern Europe, dating from the 10th to 18th centuries. Dating and regional attribution
were supported by codicological, paleographic, and linguistic criteria. All texts
were written in Cyrillic and exhibit non-normalized orthographies typical of the religious,
non-vernacular literary genre. The corpus spans a wide variety of Old Church Slavonic
recensions shaped by distinct cultural influences, reflected in the orthographic,
lexical, and morphosyntactic diversity of the material. A particularly salient phenomenon
traced here is the so called
Second South Slavic influence, which manifests in the 14th -15th century Rus’ scribal tradition through the incorporation
of South Slavic stylistic norms into East Slavic manuscript culture.
[21]
BERT-based models
[22] have been applied to sentence-level classification, segmenting texts into sentence-like
units. For fine-tuning, the study employed publicly available models on Hugging Face,
such as 1)
bert-base-multilingual-uncased and Cyrillic-specific architectures like 2)
KoichiYasuoka/bert-base-slavic-cyrillic-upos and 3)
anon-submission-mk/bert-base-macedonian-bulgarian-cased. BERT achieved high accuracy in three attribution tasks: a) manuscript identification;
b) dating by century attribution; c) regional classification, outperforming Cyrillic-specialized
models. The study demonstrated the competitiveness of general-purpose multilingual
transformers when fine-tuned on historical Slavic data. This is coherent with our
findings, as described in our own case study from section 5. (Analysis of results).
The issue of text normalization remains unresolved, along with the need to develop
analytical methodologies capable of working with non-normalized texts. Such approaches
are essential to preserve the orthographic and stylistic peculiarities of the language,
thereby enabling in-depth philological analysis that can engage in dialogue with semantic
studies and their historical, theological, and cultural significance.
The following section explores the challenges related to data scarcity and text processing,
with a particular focus on data collection aimed at developing a semantic retrieval
tool for OCS and Church Slavonic. This development is part of the broader DaMSym project,
which supports semantic similarity search not only for OCS and Church Slavonic but
also for Latin, Greek, Arabic, Sanskrit, and a combined Latin/Greek multilingual configuration.
3. Data Collection
As previously discussed, the scarcity of texts in Old Church Slavonic and Church Slavonic
has posed, and continues to pose, a significant challenge for the development of NLP
tools for these languages, and more broadly, for the training of large language models
(LLMs). This challenge can be traced to three main issues concerning the availability
of plain-text resources:
- Texts are scattered across various online repositories, stored in heterogeneous formats,
and are not encoded using a consistent Unicode font, which makes their aggregated
use difficult;
- The editorial criteria adopted are often unclear, and there is no shared agreement
on their accuracy or reliability;
- Progress in OCR and HTR methodologies remains limited, and the amount of manual intervention
still required to improve the performance of tools such as Transkribus and eScriptorium
is too substantial to enable a large-scale creation of high-quality resources.
We accounted for these issues when collecting the diachronic dataset and when developing
the semantic retrieval tool presented in this work.
For this reason, we initially chose to focus exclusively on Old Church Slavonic and
Church Slavonic textual resources written in the Cyrillic script, thereby excluding
those preserved in Glagolitic
[23].
This decision is directly related to the approach taken in the development of the
dataset and the selection of source texts. We retained the original transcriptions
provided by the selected editions but opted not to include transliterations. Although
the texts in question have already undergone editorial handling especially in terms
of normalizationprocessing, we argue that preserving the original script allows for
a more faithful and nuanced analysis, both linguistically and semantically.
This principle also informed our decision to exclude the
Corpus Cyrillo-Methodianum Helsingiense (CCMH)
[24] which was made available through the Language Bank of Finland (Kielipankki) and the
CLARINO infrastructure.
[25]
While the CCMH corpus offers transliterated versions of Old Church Slavonic texts
that may serve particular use cases, it does not meet the requirements of our framework
for semantic modeling and linguistic annotation, which relies on maintaining the original
Cyrillic representations.
Given these considerations, texts written in the Glagolitic alphabet were excluded
due to the substantial challenges involved in standardizing such sources for qualitative
analysis, particularly those arising from the use of Private Use Area (PUA) characters.
[26] As previously noted, even working exclusively with Cyrillic-script materials has
required the application of multiple Unicode fonts and, in some cases, the implementation
of customized mappings between PUA and Unicode code points to ensure accurate text
rendering. This process, which is essential for conducting reliable qualitative analyses,
would become significantly more complex with the inclusion of additional scripts.
A further example of texts that were intentionally excluded, is the Orthodox portal
Azbuyka,
[27]
particularly the section Богослужение – Священное Писание (Bogosluzhenie – Sviashchennoe
Pisanie; Divine Liturgy – Holy Scripture). These texts represent modern editions of
manuscripts reflecting liturgical language from approximately the 16th-17th centuries,
a later phase in the historical development of Church Slavonic. However, they were
excluded from the corpus due to the lack of reliable metadata
[28], particularly concerning the precise dating and provenance of the editions.
Therefore, our current focus remains limited to Cyrillic sources for which precise
metadata information could be retrieved. Once the primary issues related to PUA encoding
are resolved, we intend to expand the dataset to include Glagolitic texts, enriching
both its historical scope and linguistic depth in support of the broader objectives
of this diachronic resource.
As previously mentioned, the inclusion of Cyrillic sources underwent further refinement
based on the issue of Private Use Area (PUA) characters. For this reason, only texts
with available and compatible fonts enabling accurate rendering were included. In
the case of the
Cyrillomethodiana,
[29]
in addition to the font itself, PUA-to-Unicode mappings were introduced to facilitate
proper front-end visualization. These mappings were designed not only to support display
within the semantic retrieval tool, but also to serve as the foundation for a Unicode
character converter currently under development.
The mapping table was compiled through meticulous cross-referencing with the charts
found in
Unicode Technical Note #41
[30] specifically the sections detailing the Glagolitic Supplement and Cyrillic Unicode
blocks, as defined in
Unicode Standard Version 16.0.
[31]
Furthermore, for diacritical marks, comparative analysis was carried out with the
Unicode implementation for Ancient Greek, using the
IFAOGrec Unicode[32]
resource as a reference. The map includes 43 characters, organized according to the
following information: 1) appearance on website; 2) PUA – PUA Unicode; 3) Cyrillic
Char.; 4) Cyrillic Unicode. Among these, 16 are diacritical signs and 23 are characters.
Of the latter, 2 belong to the Glagolitic alphabet block: 1) U+2C51 - Glagolitic
Small Letter Yat; 2) U+2C49 - Glagolitic Small Letter Out. Both have been added in
Unicode version 4.1 (2005). and belong to the Glagolitic block of the Basic Multilingual
Plane.
[33]
In conclusion, the dataset used for the development of the semantic analysis tool
is compiled from the following repositories and sources:
- Cyrillomethodiana (uni-sofia.bg);
- Syntacticus (syntacticus.org);
- Old Russian Hagiographic Literature (spbu.ru);
- a subset of the National Corpus of the Russian Language (ruscorpora.ru), specifically the texts available through Universal Dependencies;
- a sample from the Ruthenian Corpus (UD_Old_East_Slavic-Ruthenian);
- the Cyrillic manuscript transcriptions from the 11th century and the transcriptions
of manuscripts from the Kazanskaya Collection, available through the manuscript.ru project.
In total the documents are: 683. The semantic retrieval carried out by the tool is
performed on these texts. Following the principle that the text to be retrieved should
not be contained in the documents on which the tool operates, among these there are
four documents that are known to contain witnesses of the Creed.
4. Methodology
This chapter describes the technical aspects underlying the functionalities of the
retrieval search system. Here, we describe the methodology used, the details of the
text parsing and preparation, and the models used and the impact of these choices
on the final tool.
4.1 Data Preparation
Each document contains the following fields:
- Title;
- Latin title;
- Original title;
- Language - categorized as follows: -
- a. Old Church Slavonic (OCS): 9th–11th centuries;
- b. Church Slavonic (CS): 12th–17th centuries (including regional redactions: Bulgarian,
East Slavic, Serbian);
- c. New Church Slavonic (NCS): 18th century;
- d. Ruthenian / Ruska mova (Rut): 15th–18th centuries;
- Century (10th–18th);
- Geographic area;
- Historical and regional variant;
- Source,
- Notes,
- Content, which contains the full text in Old Church Slavonic and Church Slavonic.
The documents span a range of centuries and originate from different regions within
the Slavic Orthodox cultural sphere. The accompanying metadata supports advanced filtering
and semantic analysis.
Among the most useful metadata fields there are 1) Century;, 2) Area;, and 3) Source,
which help contextualize the texts both chronologically and geographically. However,
the primary focus of semantic processing is the Content field. These texts vary significantly
in length and complexity. The average document contains approximately 7133 words,
with a minimum of 5 and a maximum of 280,403 words. This wide distribution required
a robust chunking strategy to make the data suitable for embedding and semantic search.
The texts originate from a variety of repositories and digital libraries. As indicated
above, a total of 6 unique source domains are represented in the dataset: this diversity
introduces variability in formatting and textual conventions, a problem that is addressed
through the use of each charset based on the input text.
4.2 Data Processing
To prepare the Old Church Slavonic and Church Slavonic textual data for semantic embedding
and search, we adopted a chunking strategy aimed at segmenting long texts into semantically
meaningful units. Chunking is crucial not only for complying with the token limitations
of transformer-based models but also for enhancing semantic retrieval accuracy and
contextual coherence.
We used a rule-based sentence segmentation approach using spaCy2’s multilingual blank
model (spacy.blank("xx")). Since there is no dedicated model for Old Church Slavonic
in spaCy, we added a lightweight rule-based splitter component to split the text using
a punctuation-based methodology. To ensure manageable and semantically coherent segments,
we implemented a chunking routine with the following configuration:
- Target chunk size: 75 words
- Minimum size: 50 words
- Maximum size: 100 words
- Overlap strategy:
- For chunks within size bounds, we attached 2 sentences before and after the chunk
to provide contextual continuity.
- For oversized chunks, we used a sliding window to split the chunk into smaller sub-
chunks, each followed by left/right context built from adjacent tokens.
Each chunk record includes:
- The chunked text
- The context_before (up to 2 preceding sentences)
- The context_after (up to 2 following sentences)
- All original metadata fields from the document source
This approach provides flexibility and ensures that both short and long passages retain
enough semantic context to be effectively indexed and retrieved during search.
4.3 Model Implementation
To enable semantic retrieval, each chunk of Old Church Slavonic and Church Slavonic
texts was converted into a high-dimensional numerical representation known as an embedding.
These embeddings allow us to compare textual passages based not on exact keyword overlap
but on semantic similarity, which is crucial for working with a historic and morphologically
rich language like (Old) Church Slavonic.
Embeddings are central to our semantic pipeline because they allow us to:
- Measure conceptual similarity between phrases, even if they differ in vocabulary.
- Support natural language queries that retrieve thematically related content.
- Enable fast vector-based search via cosine similarity in vector databases like Qdrant.
Initially, we tested bert-base-multilingual-uncased, a general-purpose multilingual
model. However, during the evaluation phase, the results yielded low similarity scores
and imprecise semantic matches. This indicated that the model lacked the representational
nuance needed for the historical and liturgical nature of our corpus. As a result,
we transitioned to jinaai/jina-embeddings-v3 (Sturua et al., 2024), one of the most
downloaded and performant multilingual models currently available for text embedding.
It is designed for high-quality retrieval use cases and better aligned with our requirement
to embed non-standard historical scripts.
The cleaned and chunked dataset was processed in batches of 16 to optimize GPU memory
usage. For each batch:
- Text chunks were tokenized and fed into the Jina model.
- The embedding vector was extracted from the model’s [CLS] token (i.e., outputs.last_hidden_state[:,
0, :]), cast to float32 to avoid type issues.
- A custom text_to_display field was constructed using the pattern:
- Context_before <mark> Chunk </mark> Context_after
- This format enhances readability and context comprehension in the frontend interface
by highlighting the core chunk while preserving its semantic surroundings.
- A payload dictionary was built for each chunk, containing all metadata from the original
dataset and the newly created text_to_display field
- Each entry was wrapped in a Qdrant PointStruct, assigned a unique UUID, and uploaded
to the local Qdrant vector store.
In total, every chunk from the corpus was embedded, wrapped with metadata and context,
and indexed in Qdrant. This embedding infrastructure provides the semantic backbone
of the search engine, enabling linguists and scholars to explore Old Church Slavonic
and Church Slavonic documents with precision and contextual awareness, even when queries
do not directly match the original wording.
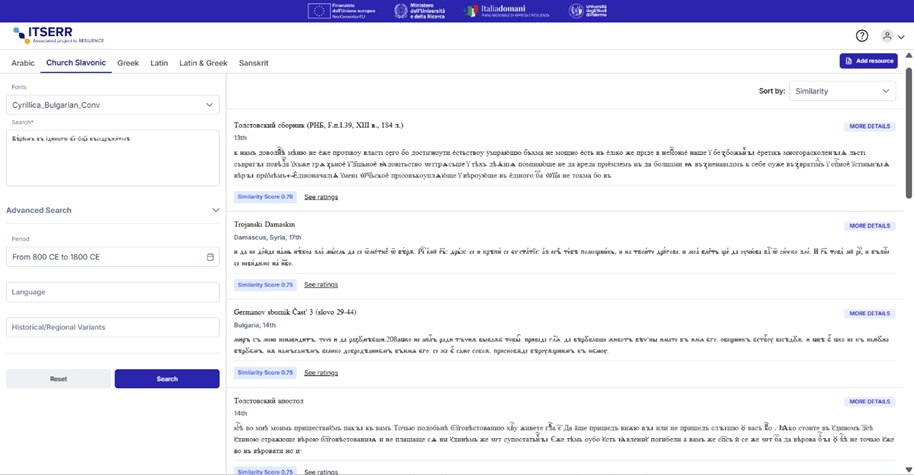
4.4 User Interface
The User Interface provides the following key features:
- Query panel
- Text area to input the search query
- Select boxes to choose the corpus and the corresponding model
- Similarity Score and Top-K Results inputs to let users define the strictness of the
results. And enable filtering based on semantic proximity
- Search button to initiate the request
- Filter Panel
- Dynamically populated autocomplete filters based on metadata returned from the backend
.
- Filter and Reset buttons allow users to refine or reset their search easily.
- Results Display Panel
- Results are shown as a list of box items, paginated in groups of 5.
- Each item displays the highlighted chunk of text using <mark> tags to emphasize the
matched portion.
- An Accordion expands to reveal metadata for each result.
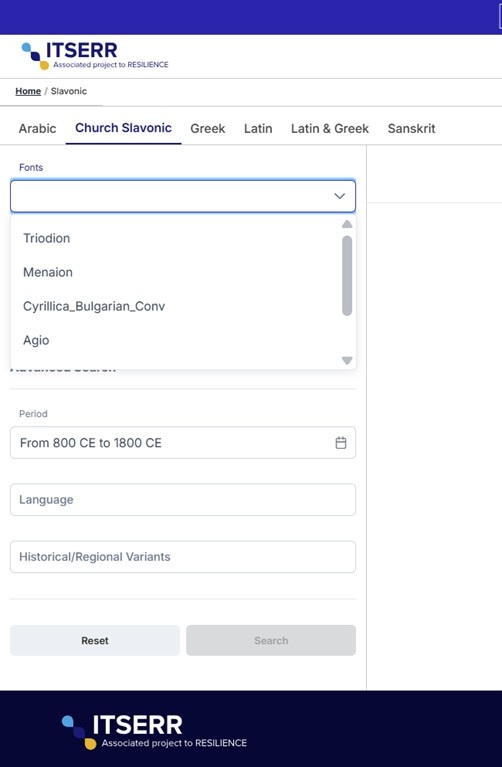
To ensure accurate visual rendering of Old Church Slavonic texts, the frontend applies
specific fonts dynamically based on the domain listed in the Source metadata field.
Since the documents were aggregated from various online repositories each relying
on its own typographic conventions to represent extended Cyrillic and historical glyphs
this approach preserves the visual fidelity of the original sources. The platform
supports five custom fonts, each associated with a corresponding domain:
| Custom Fonts |
Platform Interface Label |
- github-ocs font for texts from
- syntacticus.org;
- UniversalDependencies/UD_Old_East_Slavic-RNC;
- UniversalDependencies/UD_Old_East_Slavic-Ruthenian
|
Syntactivus_ |
- cb10u font for texts from histdict.uni-sofia.bg
|
Cyrillica_Bulgarian_Conv |
- menaion font for texts from manuscripts.ru
|
Menaion |
- AGIO font for texts from project.phil.spbu.ru
|
Agio |
These fonts have been integrated into the platform : their identification and implementation
in the tool were essential requirements to enable the correct visualization of results.
In some cases, as already mentioned, the integration of Unicode fonts must be accompanied
by the PUA - Unicode mapping, since only this combination ensures correct rendering
also on the frontend. This approach has already been applied to the texts of the
Cyrillomethodiana web portal, while it is still under development for other texts whose character maps
are currently being defined. In its final version, As shown in the table (Platform
Interface Label), tthe tool will include a specific filter allowing users to select
the combination of Unicode font + PUA map - Unicode.
[34]
The font filter has been designed as a field that can be dynamically configured by
incorporating fonts available online in open access, as well as additional mapping
tables between Private Use Area (PUA) characters and Unicode characters created manually.
Members of the project’s editorial board can access the dashboard and add new fonts
by specifying the label designation, the source domain, and the file in one of the
supported formats (.woff, .woff2, .ttf). Once saved, the font becomes selectable from
the font list available prior to the text input field used for searchable queries.
This domain-aware font assignment ensures that special characters unique to Old Church
Slavonic are correctly displayed in the user interface, enhancing readability and
historical authenticity.
5. Analysis of Results
[
Feliksov 2018] has noted that the language of Orthodox doctrine, although well consolidated in
liturgical practice and written tradition, lacks a structured grammar or a comprehensive
descriptive model capable of accounting for the syntactic, semantic, and morphological
peculiarities of its core terms. From his perspective, this absence leads to:
- difficulties in the linguistic analysis of vocabulary: as Orthodox vocabulary contains
semantically dense units deeply rooted in theological meaning, many of which do not
easily conform to standard grammatical categories. The main challenges involve:
- the polysemy of key terms (e.g., благодать –blagodat- grace),
- their strong interdependence on liturgical context,
- the lack of direct correspondences in modern and everyday language.
- difficulties in grammatical and semantic encoding: the current linguistic description
of Orthodox lexicon is fragmented and often limited to encyclopedic dictionaries or
glossaries, which typically do not offer coherent morphological or syntactic analysis.
This creates obstacles for structured teaching and for computational formalization
(e.g., annotation, parsing, semantic processing) of this type of vocabulary.
To address these issues, a semantic approach is proposed, that aims to describe the
complexity and richness of the vocabulary of Orthodox faith in Church Slavonic, by
incorporating:
- analysis of syntactic roles within the sentence,
- discourse function in liturgical usage,
- semantic and theological relations among terms.
The linguistic methodology underpinning this study is based on the ontological theory
of language, grounded in the ideas of Orthodox doctrine on being and the word, as
developed by [
Florenskii 1990]; [
Losev 1993]; [
Kamchatnov 1998]; [
Bulgakov 2007]; [
Aksakov 2011] and [
Postovalova 2022]. Central to this theory is the concept of the “eidosphere”, understood as an instrument
to designate the set of lexical and phraseological units, as well as non-predicative
(nominative) word combinations "generated" by a given eidos through the act of naming.
The study adopts the term “lexico-eidetic group” (LEG), as introduced by Kamchatnov.
This notion is rooted in the Christian intuition that God
“creates simultaneously both the thing and its idea, in their indivisibility and inseparability” [
Kamchatnov and Nikolina 2008, 37].
The ontological approach to language fundamentally relies on the deductive method
of semantic, accordingly, the first step toward constructing a semantic classification
of Orthodox faith vocabulary should consist in a systematic description of the “world”
of eidē that constitute the content of the eidosphere of “Orthodox Faith.”
Our work on the study of the semantic value of sentence and word is based on a different
methodological premise, although it aims to capture the polysemy of specific terms
and to investigate the diachronic evolution of Orthodox vocabulary.
First and foremost, our research aims to analyze individual sentences starting from
the context in which they appear, thus proceeding from semantic retrieval at the phrasal
level. Additionally, the research is conducted with reference to a specific text,
namely the Nicene-Constantinopolitan Creed, a brief doctrinal and liturgical formulation
that conveys the core principles of the Christian faith.
Gezen, as previously mentioned, in his book Istoriia slavianskogo perevoda Simvola very Istoria slavianskova perevoda Simvol veri (published in 1884; second edition: 2015), notes that the Slavic translation of the
Creed predates the missionary work of Saints Cyril and Methodius, although its final
redaction could only occur after the invention of the Slavic alphabet. As a text regularly
recited during the liturgy, the Creed has exerted a profound influence on the target
culture. Therefore, due to its catechetical role, the semantic implications of its
vocabulary, particularly the theological significance of linguistic and terminological
variants, are of special relevance.
This research, consequently, is motivated by the intention to trace the influence
of the Greek liturgical tradition on the Slavonic versions of the Creed, and to study
their reception across different regions and historical stages in the development
and use of the language.
The research sets out to examine two key questions:
- the ability of the tool to retrieve phrases that are semantically related to selected
articles from the Nicene-Constantinopolitan Creed;
- the tool’s ability to provide useful references for analyzing the textual revisions
introduced in the Creed during the liturgical reform of Patriarch Nikon (1653-1656).
These revisions, which aimed to restore consistency between the Russian Orthodox liturgical
tradition and the Byzantine tradition, involved not only orthographic corrections,
but also terminological changes whose historical and theological significance has
been widely discussed in the scholarly literature.
For this reason, the presentation of results will proceed in two parts:
- The first section will be based on an in-depth analysis of two selected articles from
the Creed and will address both objectives.
- The second section will examine the results of user tests conducted independently
by six scholars and professors with expertise in the field of Slavic studies and digital
humanities.
These tests will focus on:
- the functionality and usefulness of the tool
- the accuracy of its outputs in relation to the self-selected article and version of
the Nicene-Constantinopolitan Creed.
5.1 Analysis of Results - Section One
A particularly significant example, from this perspective, concerns the verbal tense
used for the verb “to be.” In the seventh article of the Creed, which refers to the Kingdom of God, the original
Slavonic formulation нѣсть конца несть конца (nest’ kontsa – “there is no end”) was revised during Patriarch Nikon’s liturgical reform to не будет конец (ne budet konez – “there will be no end”).
This modification implied a theological shift: the Kingdom of Christ was no longer
understood as an eternal reality already inaugurated through His incarnation, crucifixion,
and resurrection, but rather as a reality postponed to the future. The pre-reform
version of this article corresponds to the formulation found in the earliest Slavic
recension of the CreedSymbol of Faith
#gezen1884.
A comparison of the results returned by the tool for the queries “нѣсть кѡнца несть
конца” and “не бꙋдетъ не будет конец” reveals important insights into how the linguistic
retrieval system operates, particularly its ability to function on both formal and
semantic levels.
In the case of the first query, нѣсть кѡнца несть конца (Table 1), the tool does not detect any literal occurrence of this phrase in the
examined texts. However, it correctly retrieves a semantically equivalent expression
- не будет кѡнца конца - attested in the Codex Laurentianus (12th century, Kyiv Pechersk Lavra, Old Church Slavonic).
The fact that the tool does not retrieve the expression is rather unexpected, given
that the dataset is known to contain at least four versions of the Creed in its pre-Nikonian
form that include the expression “нⷭ҇ѣ кѡнца̀”. It is not possible to determine with
certainty whether these are the only instances present in the dataset; however, even
in this case, the absence of any reference to these texts among the results must be
regarded as a limitation of the tool. This issue clearly underscores a weakness of
the system, confirming the findings that also emerged from user feedbacks. Several
factors may explain the observed limitation. First, it is important to emphasize that
the goal of the tool is to retrieve semantically related sentences, rather than sentences
that merely correspond at the linguistic level. This objective has significantly influenced
the preparation of Old Church Slavonic texts for embedding and semantic retrieval,
leading to the adoption of a chunking strategy aimed at segmenting longer textual
passages into semantically meaningful units. Such an approach was necessary both to
comply with the token limitations of transformer models and to ensure semantic accuracy,
as well as coherence with the broader textual context.
However, although there is a grammatical difference between the two phrases (present
vs. future tense), both convey the same eschatological meaning: the eternity of Christ’s
Kingdom. The fact that the tool retrieves a morphosyntactic variant that does not
exactly match the query demonstrates its ability to go beyond literal pattern matching,
incorporating a semantic component capable of identifying differently formulated yet
semantically equivalent expressions.
This pattern is also confirmed in the second query, не бꙋдетъ кѡнец, (Table 2), where in addition to retrieving the exact textual match (again in the
Codex Laurentianus), the system also identifies other doctrinally relevant passages, even in the absence
of the explicit phrase - such as those found in the Poouchenie za spasenieto na dushata (14th century, Russia) and the Dialogi (15th century). In both cases, the retrieved texts address similar eschatological
themes, the eternal Kingdom, judgment, and salvation, although these are formulated
paraphrastically, e.g. “царство, уготованное от созданїѧ мирацарство, уготованное от создания мира” (“the Kingdom prepared from the foundation of the world”) or “црⷭ҇твовати вѣчно и бесм҃ртно (“to reign eternally and immortally”).
As a result, it is evident that the tool can retrieve sentences that are semantically
related to the initial query, based on contextual similarity. In some cases, however,
the tool is also capable of detecting literal similarity. These capabilities are further
supported by the qualitative assessment made by specialists in the humanities.
Such behavior proves particularly valuable in the analysis of religious or patristic
texts, where doctrinal content is often conveyed through variable formulas that remain
thematically recognizable. The tool demonstrates suitability for scholars seeking
semantically related results. Nevertheless, literal matches are preserved as well,
since the tool does not impose any antinomy between them. This feature allows for
its implementation in philological, theological, and diachronic lexicographic research.
The replacement of the formula нѣсть кѡнца несть конца with не бꙋдетъ кѡнца in the seventh article of the Symbol of FaithCreed, implemented during Patriarch
Nikon’s liturgical reform, does not constitute a mere morphosyntactic variation, but
rather a profound doctrinal shift: a transition from an understanding of the Kingdom
as already present and active in history to a future and deferred conception. In this
context, the use of automated semantic query tools, such as the one under examination,
offers a novel and concrete perspective for verifying how and where these two formulations
are actually documented in Slavonic texts, and which of the two is attested across
different historical periods and ecclesiastical settings.
The tool’s main strength, in this regard, lies in its ability to recognize and connect
semantically related expressions, even when they exhibit morphological or syntactic
variation. Starting from the query нѣсть несть кѡонца, the pre-Nikonian form, the system retrieves не бꙋдетъ кѡнца, attested in an authoritative text such as the Codex Laurentianus (12th century), thereby revealing that the future-tense formulation was already in
use well before the reform, albeit not yet canonized liturgically. This information,
which emerged precisely through automated retrieval, challenges the narrative of an
absolute rupture introduced by Nikon, confirming instead a process of selection and
formalization of already existing variants.
In the eighth article of the Creed, the removal of the adjective
истиннагѡ истиннаго (
istinnago - “true”) referring to the Holy Spirit is regarded by some scholars as the only truly
significant revision introduced by Patriarch Nikon. [
Shakhov 1997], in his study analyzing the Old Believers’ stance on the revisions enacted through
Nikon’s liturgical reform, emphasizes that the Old Russian translation, which included
the adjective “true” as a descriptor of the Holy Spirit, was intended to convey the
theological assertion that the Spirit shared equal status with the other persons of
the Trinity. Nikon’s decision to omit the adjective thus undermined this assertion,
subordinating it to the objective of achieving grammatical and stylistic conformity
with the Greek version of the Creed.
A comparison of the tool’s output in response to queries based on the formula “И въ Дꙋха Свѧтаго, Господа животворѧщаго, иже от Отца исходѧщаго И в Духа Святаго
Господа животворящаго иже от Отца исходящаго - I v Dukha Sviatago, Gospoda zhivotvoriashchago,
izhe ot Ottsa iskhodiashchago - And in the Holy Spirit, the Lord, the Giver of life,
who proceeds from the Father” (Table 3) yields relevant data regarding the dissemination, reformulation, and lexical
stability of this article of the Symbol of FaithCreed within the Slavic Orthodox tradition.
In none of the analyzed texts, dating from the 12th to the 15th century, does the
formula appear in its complete canonical form. Nonetheless, the tool makes it possible
to trace the gradual appearance of its constituent elements across various liturgical,
homiletic, and theological contexts.
In Table 3, for instance, the word Господа (“Lord”) is consistently attested with reference to Christ, but not to the Holy Spirit,
while the term истиннагѡ истиннаго (“true”) appears only once, and likewise refers to the Son. The component животворѧщаго животворящаго (“life-giving”), which is central to the pneumatological articulation of the Creed,
is entirely absent, except perhaps in implicit or descriptive form.
A similar pattern emerges in Table 4, where terminology related to the Holy Spirit
appears more vaguely and fragmentarily: for example, in the Uchitelno evangelie Учително евангелие (12th century), the Holy Spirit is referred to as д͠хъ с͠тыи ( dukh sviatyi “holy spirit”), and His withdrawal is described as marking the end
of prophecy. However, neither the title “Lord” nor the epithet “life-giving” is used.
Only in the later liturgical text Oustav bozh(ʹ)estvennyia sluzhby sviatago apostola Iakova, which appear as result in both searches, does a formulation occur that is nearly
complete and semantically equivalent to that of the Nicene-Constantinopolitan Creed:
here, the Spirit is referred to as животворѧщимъ… дꙋхомъ (“life-giving... Spirit”) and is explicitly associated with the Father and the Son
in a solemn liturgical context that aligns with Orthodox Trinitarian doctrine.
From a methodological standpoint, the qualitative analysis conducted by a humanities
specialist indicates that the tool employed demonstrates a solid capacity to recognize
semantically equivalent or related structures, even when the queried formulation is
not attested in a literal form. Its accuracy is particularly evident in the identification
of the 17th -century liturgical source, but also in its ability to retrieve elements
dispersed across time and space. This provides a valuable foundation for investigating
the historical development of the requested formula, as well as the ways in which
it was received and adapted in textual and liturgical practice.
The research shows that the adjective истиннагѡ истиннаго (“true”) is rarely attested in the examined texts and, when it does appear, it is
applied to the Son or to God in a general sense, not to the Holy Spirit. The tool
accurately highlights this absence, demonstrating that the complete formulation with
истиннагѡ истиннаго referring to the истиннагѡ referring to the дꙋхъ (Spirit) is neither widespread nor stable within the pre-reform tradition. Consequently,
Nikon’s revision can be interpreted not only from a theological perspective but also
as a redactional normalization of an expression that had little support in the earlier
liturgical corpus.
At the same time, the tool demonstrates the ability to recognize partial, semantically
or liturgically related formulations, identifying fragments that testify to the progressive
doctrinal elaboration of the formula. In particular, the retrieval of the sentence
“и животворѧщимъ твоимъ Дꙋхомъ и животворящим твоим Духом - i zhivotvoriashchim tvoim
Dukhom - and with your life-giving Spirit” only in late liturgical texts (17th century) may help in the definition of a concrete
mapping of the moment when the formula became stabilized in its new-canonical version.
On this basis, a more comprehensive study could be undertaken in the future, extending
the scope to all articles of the Creed, as well as to other texts, in order to analyze
their relationship to the broader historical context that may have influenced both
their translation and the revisions introduced in the 17th seventeenth century. Such
research would naturally align with the previously mentioned studies devoted to the
historical and theological significance of Patriarch Nikon’s reform.
| Query |
Results |
Exact text: “несть конца” |
Equivalent Expression |
Semantic Relevance |
| и паки грядущаго со славою судити живымъ и мертвымъ, Егоже Царствию несть конца. |
|
|
|
|
|
и ѡтсуду иꙁбавлѣнью сподобимъсѧ . и тамо вѣчнꙑꙗ̇ жиꙁни наслѣдници будемъ небоно дх҃овноѥ̇
подвиꙁаньє или на супротивнаго побѣдѣ страⷭ҇ю̇ . и смр҃тью бꙑваѥть стражющеи и оумерщьвѧюще
оудꙑ телѣснꙑꙗ хⷭ҇а ради ѥдинодш҃ьно побѣдимъ супротивьнаго . тѣмьже всѧкꙑ скерби и
напасти . и въстаньѥ вселукаваго . нѣ въ болѣꙁнехъ имѣти . но въ доброврѣмиѥ трепѣниꙗ
желающе.
Title: Сборник поучений Ефрема Сирина Сборник поучений Ефрема Сирина ("Паренесис Ефрема
Сирина")
Century: 13th;
|
✘ No |
✘ No |
Talks about resurrection, suffering, and judgment: "и тамо вѣчнꙑꙗ̇ жиꙁни наслѣдници
будемъ""and there we shall become heirs of eternal life" |
|
тогда жалостью въскричитьвсѧка дш҃а и всѧкъ чл҃вкъ годъѹпустившє и ѡⷮвѣщаѥть имъправєдныи
судии ижє ны многотєрпѣ идѣтє проклѧтии ѡⷮ мєнєвъ огнь вѣчныи пакы жє къст҃мъ грѧдѣтє
блгⷭ̄нии о҃ца моѥгопридѣтє въ ѹготовано вамъцрⷭ̄тво ѡⷮ съставлєниꙗ мира всєго.ѥмужє
слава и вєлєлѣпьѥ чєстьжє и миръ и блгнⷭ̄иѥ ѡⷮ всєꙗтвари съ прєст҃ымь оц҃мьи животворѧщимь
дх҃омь нынѧи приⷭ̄.
Original_title: Поучение за спасението на душата;
Century: 14th;
Language: Church Slavonic
|
✘ No |
✘ No |
Refers to the kingdom “prepared since the foundation of the world”, but no mention
of unending reign."придѣтє въ ѹготовано вамъ црⷭ̄тво ѡⷮ съставлєниꙗ мира всєго""Enter
into the kingdom prepared for you from the foundation of the world" |
|
не будет конца сица же будть мч҃нья иже не вѣруеть къ б҃у нашему іс҃у хсу мч҃ми будут
в огни иже сѧ не кртсить и се рекъ показа володимеру запону на неиже бѣ написно судище
гсне показываше ему ѡ десну прв҃дныя в весельи предъидуща в раи а ѡ шююю грѣшники
идуща в муку володимеръ же вздохнувъ реч добро симъ ѡ десную горе же симъ ѡ шююю ѡнъ
же реч аще хощеши ѡ десную съ првд҃нми стат
Title: The Primary Chronicle, Codex Laurentianus
Century: 12th; Source: https://github.com/torottreebank/treebank-releases/blob/master/lav.conll
Language: Old Church Slavonic
|
✘ No |
✔ "не будет конца" |
Direct future-tense equivalent of “несть конца” — “there will be no end”. Fully aligns
with the phrase. |
Table 2.
Text of the Nicene – Costantinopolitan Creed is from
Sledovannaya Psatir'- 1653 (For further information on the transcription, see [
Napolitano 2025]).
| Query |
Results |
Exact text "не будет конец" |
Equivalent Expression |
Semantic Relevance |
| И паки грядущаго со славою судити живым и мертвым, егоже царствию не будет конец. |
|
|
|
|
|
тогда жалостью въскричитьвсѧка дш҃а и всѧкъ чл҃вкъ годъѹпустившє и ѡⷮвѣщаѥть имъправєдныи
судии ижє ны многотєрпѣ идѣтє проклѧтии ѡⷮ мєнєвъ огнь вѣчныи пакы жє къст҃мъ грѧдѣтє
блгⷭ̄нии о҃ца моѥгопридѣтє въ ѹготовано вамъцрⷭ̄тво ѡⷮ съставлєниꙗ мира всєго.ѥмужє
слава и вєлєлѣпьѥ чєстьжє и миръ и блгнⷭ̄иѥ ѡⷮ всєꙗтвари съ прєст҃ымь оц҃мьи животворѧщимь
дх҃омь нынѧи приⷭ̄.
Title: Поучение за спасението на душата;
Century: 14th;
Language: Church Slavonic;
|
✖ No |
✔ Reference to the return of Christ and to the Kingdom prepared "от создания мира"“from
the foundation of the world” |
Semantically related (Second Coming, Judgment, Kingdom)
|
|
не будет конца сица же будть мч҃нья иже не вѣруеть къ б҃у нашему іс҃у хсу мч҃ми будут
в огни иже сѧ не кртсить и се рекъ показа володимеру запону на неиже бѣ написно судище
гсне показываше ему ѡ десну прв҃дныя в весельи предъидуща в раи а ѡ шююю грѣшники
идуща в муку володимеръ же вздохнувъ реч добро симъ ѡ десную горе же симъ ѡ шююю ѡнъ
же реч аще хощеши ѡ десную съ првд҃нми статTitle: The Primary Chronicle - Codex Laurentianus;
Century: 12th; Source: https://github.com/torottreebank/treebank-releases/blob/master/lav.conll
Language: Old Church Slavonic;
|
✔ не будет конец |
|
Partially related (Judgment, salvation/damnation)
|
|
по настающиⷨ вѣцѣ. нетлѣннїи и бесм҃ртнии. въстающе прⷭ҇но пребываеⷨ. оле саⷨ тъ ѹбо
всѣⷨ. исконныи хытрець и строитель. къ ѡ҃цѹ пакы дошеⷣ не пребѹдет ли. какоⷤ҇ и црⷭ҇твовати
вѣчно и бесм҃ртно съ ниⷨ чл҃вкоⷨ ѡбѣщаваеⷮ. а саⷨ того лишаеⷨ. и кончаниеⷨ црⷭ҇тво
ѿлагаѧ по сѹемысльныиⷨ. но ѡстани сѧ беꙁѹмиѧ того молю тѧ. обличиⷮ бо ихъ въ древнїиⷯ
дв҃дъ ѡ х҃ѣ поа ц҃рьствѣ. исповѣдѧть ти сѧ гⷭ҇и всѧ дѣла твоа.
Title: Диалози;
Century: 15th;
|
✖ No |
✔"црⷭ҇твовати вѣчно и бесм҃ртно" |
Semantically related: eternity of the Kingdom |
Table 3.
ext of the Nicene – Costantinopolitan Creed is from
Acts of the 1654, 1655, 1656 Councils (For further information on the transcription, see [
Napolitano 2025])
| Query |
Results
|
Exact word “Господа” |
Exact word “истиннаго” |
Exact word “животворящаго” / semantico equivalente |
Equivalent expression |
Semantic Relevance |
| И въ Духа Святаго Господа истиннаго и животворящаго, иже от Отца изходящаго |
|
|
|
|
|
|
|
тѹне и дадите ѡ сихъ бо и самъ г҃ь рече вѣрѹꙗи въ мꙗ дѣла ꙗже азъ творю и тъ сътворитъ
и больша тѣхъ нъ о блаженаꙗ страстотьрпьца хр҄сва не забꙑваита отьчьства идеже пожила
ѥста въ тели ѥгоже всегда посѣтъмь не оставлꙗета тако же и въ мл҃твахъ вьсегда молита
сꙗ о насъ да не придеть на нꙑ зъло и рана да не пристѹть къ телеси твоѥмѹ и рабъ ваю
вама бо дана бысть бл҃годать да молита
Title: Uspenskij sbornik;
Century: 13th;
Language: Church Slavonic;
|
✔ “г҃ь” (“Господь”) |
✘ No |
✘ No |
|
Reference to Christ and to prayer, but no specific mention of the Holy Spirit or the
attributes “true” (истиннаго) and “life-giving” (Животворящаго) |
|
и оутвръждаѧй въсѧ вѣроуѫщѧѧ къразоумоу неблазньномоу и исповѣданїꙋ опасномоу и слоужбѣблагочьстивѣй
и покланѣнїꙋ доуховномоу и истинномоубога и ѡтца и єдинороднааго єго сына, господа
и боганашего Ісоуса Христа, и своемоу коемоуждо именю именꙋемомоу187свойство ꙗвѣ намь
благорасѫждаѫщоу и о коемждоѡт именоуемыих въсѣко нѣкымь изрѧднымь свойствомьблагочьстивѣ
зримо, ѡтцꙋ оубо въ своиствѣ ѡтчьстѣмь,сыноу же въ свойствѣ сыновнѣмь, свѧтомомоу
же доухоувъ своемь свойствѣ, ни свѧтомоу доухоу ѡт себе глаголѧщоу,ниже сыноу ѡт себе
что творѧщоу и ѡтцꙋ оубопосилаѫщоу сына, сыноу жеOriginal_title: Похвално слово за
Йоан, епископ Поливотски;
Century: 15th;
Language: Church Slavonic;
|
✔ “господа… Ісоуса Христа” |
✔ “истинномоу” |
✘ No |
|
It refers to Christ, not to the Holy Spirit. ‘Истинному’ is used in reference to God
and the Son, not to the “Духа” (Spirit).” |
|
и тѣлеса,ꙗкѡ да достойни бꙋдемь причастницы и ѡбещницы пречистымьтвоимь тайнамь во
ѡставленїе грѣхѡв и в жизньвѣчнꙋю –Возгласъ: Благодатїю и щедротами и человѣколюбїемединороднагѡ
сына твоегѡ, с нимже благословеньеси с пресвѧтымъ и благимъ и животворѧщимъ твоимъдоухомь
нынѣ и приснѡ.Молитва: Свѧтый, иже во свѧтыхъ почиваѧй,господи боже нашъ, ѡсвѧти нась
словомь твоеѧ благодатии наитїемъ пресвѧтагѡ доуха, самь бо рекль еси: Свѧтибꙋдите,
ꙗкѡ азъ свѧть есмь, господь богъ вашь.
Title: Оуставъ бож(ь)ственныѧ слꙋжбы свѧтаго апостола Іакѡва, брата господнѧ;
Century: 17th;
Language: Church Slavonic;
|
✔ “господи боже нашъ” / “господь богъ” |
✔ No |
✘ No |
“животворѧщимъ твоимъ доухомь”
|
Direct correspondence: this passage explicitly refers to the Holy Spirit as “life-giving”,
in a liturgical context consistent with the Creed.“с пресвѧтымъ и благимъ и животворѧщимъ
твоимъ доухомь” |
Table 4.
Text of the Nicene – Costantinopolitan Creed is from
Sledovannaya Psatir'- 1653
| Query |
Results
|
Exact word “Господа” |
Exact word “животворящаго” / equivalente |
Reference to “Holy Spirit” |
Semantic relevance |
| И в Духа Святаго Господа животворящаго иже от Отца исходящаго, иже со Отцем и Сыном
спокланяема и сославима, глаголавшаго пророки. |
|
|
|
|
|
|
ꙗко бѣ благодать ѥго отѧта. сего ради рече. не оубо бѣ д͠хъс͠тыи данъ. небѣ бо оуже
пророкъ въ нихъ. ниприꙁираше благодать с͠та ихь.и понѥже оуже оудрьжалъсѧ бѣ д͠хъ
с͠тыи.49cхотѣаше бо богатьно благодатьиꙁлити. сего жераꙁдааниꙗ начатъкъ. по пропѧтии
бысть.сего ради рече ꙗко ї͠с нѣ оу бѣ прославленъ. славоуже пропѧтьꙗ е наричеть.
Title: Учително евангелие
|
✘ No |
✔ “д͠хъ с͠тыи” |
✔ Semantically related – the passage explicitly refers to the Holy Spirit, focusing
on the theme of divine grace |
✘ Partial – correct context, but without the required terms
|
|
и̇просвьтет сѧ ꙗ̇ко-и̇ сл͠нце. а̇. 2грѣшници бѫⷣть тьмни, и̇ пакӹрѣхь г͠и. вси ли
крьщенӹи̇ вь е̇динѫ мѫкѫ грѫⷣть. цр͠ие̇ и̇ патриа̇рс̋и, и̇ кнѧꙁӹ и̇ богатӹи̇ и̇ ꙋбоꙁӹи̇.
слӹши праведнӹ їѡⷡ҇анє.ꙗ̇коже реⷱ҇ пророкь дав͠дь. трьпѣниє̇ оу̇б͠гӹхь не погӹбнетьдо
конц̋а. а̇ патриа̇рс̋и и̇ кнѧꙃїи̇ ꙋбоꙁӹ и̇ богатїи̇. погӹбнѫтьꙗ̇ко-и̇ скоть, и̇ вьсплачѫть
сѧ.ꙗ̇ко-и̇ младенц̋и.
Title: Berlinski sbornik
Original_title: Берлински сборник
|
✘ No |
✘ No |
✘ No |
✘ Partially related – the eschatological context is compatible, but there is no explicit
reference to the Holy Spirit or to the Trinitarian elements of the Creed. |
|
и тѣлеса,ꙗкѡ да достойни бꙋдемь причастницы и ѡбещницы пречистымьтвоимь тайнамь во
ѡставленїе грѣхѡв и в жизньвѣчнꙋю –Возгласъ: Благодатїю и щедротами и человѣколюбїемединороднагѡ
сына твоегѡ, с нимже благословеньеси с пресвѧтымъ и благимъ и животворѧщимъ твоимъ
доухомь нынѣ и приснѡ. Молитва: Свѧтый, иже во свѧтыхъ почиваѧй,господи боже нашъ,
ѡсвѧти нась словомь твоеѧ благодатии наитїемъ пресвѧтагѡ доуха, самь бо рекль еси:
Свѧтибꙋдите, ꙗкѡ азъ свѧть есмь, господь богъ вашь.
Title: Оуставъ бож(ь)ственныѧ слꙋжбы свѧтаго апостола Іакѡва, брата господнѧ; Century: 17th;
Source: https://histdict.uni-sofia.bg/textcorpus/show/doc_210; Language: Church Slavonic; |
✔ “господи боже нашъ” |
✔ “животворѧщимъ…доухомь” |
✔ |
✔ |
Table 5.
Text of the Nicene – Costantinopolitan Creed is from
Acts of the 1654, 1655, 1656 Councils
5.2 Analysis of Results – Section Two
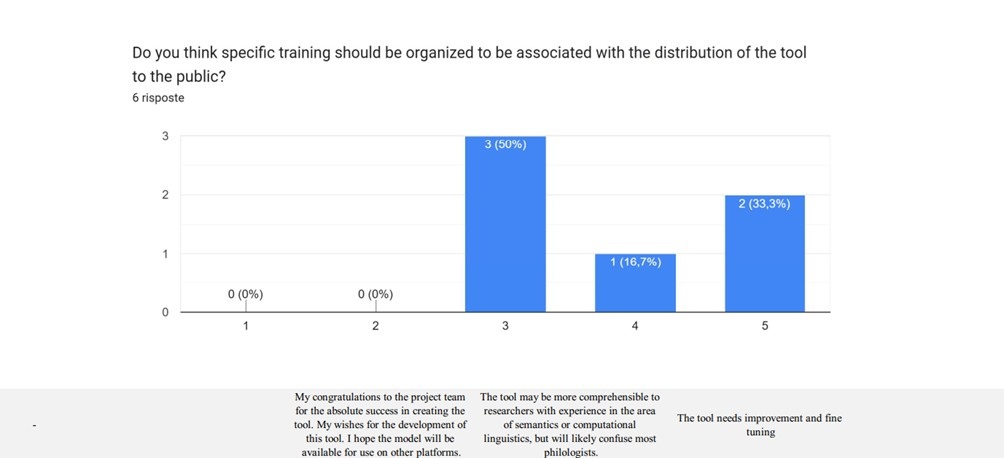
The analysis of responses to the structured test shows that the tool developed for
semantic retrieval of sentences in (Old) Church Slavonic was evaluated positively
in terms of its core functionality and its usefulness for specialized research. Nonetheless,
it still shows room for improvement, particularly in the conceptual coherence of its
results. Participants conducted their queries based on various versions of the Nicene-Constantinopolitan
Creed, including the Sledovannaya Psaltir’ of 1653, an early manuscript witness (Zogh. 105, f. 141r), the modern version taken
from Wikipedia, the PSGP.ru website, as well as a reformulation recalled from memory.
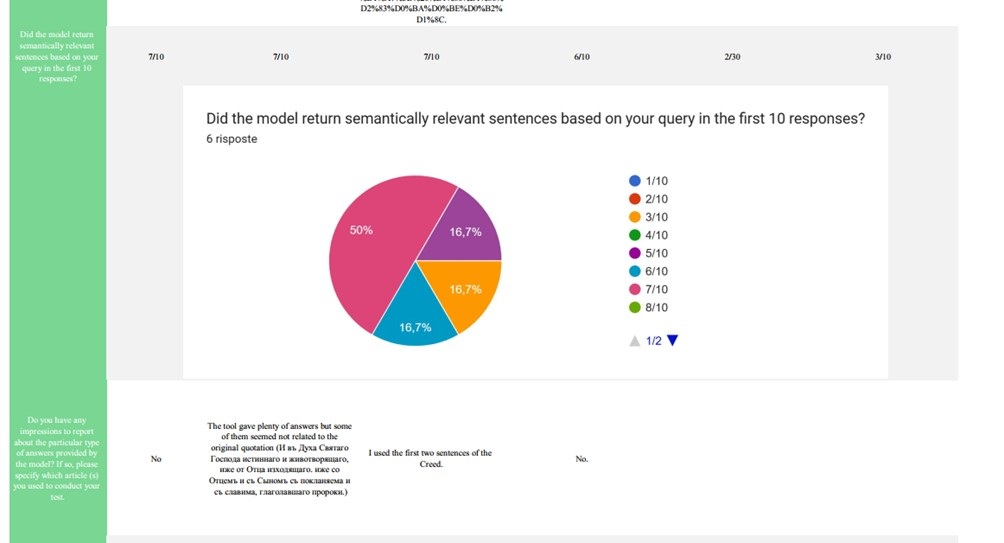
When asked to evaluate the semantic relevance of the top 10 retrieved results, the
majority of participants gave positive ratings: three users reported 7 out of 10,
one reported 6 out of 10, while two others gave lower scores (3 out of 10 and 2 out
of 10). In at least three cases, users acknowledged the system’s ability to identify
semantically related, though not always central, results. The comments and feedback
provided by the participants are summarized in the table below, along with an analysis
based on the tool’s characteristics and stage of development.
The comments collected through the questionnaires (see the table below for details)
indicate that the proposed functionalities are regarded as innovative, despite the
limitations highlighted in this feedback and discussed throughout the article. From
the perspective of advancing research in NLP and (Old) Church Slavonic, the results
can be considered positive based on the collected opinions. Future work is expected
to address the identified issues, both in terms of the tool’s functionality and the
application of NLP techniques to Old Church Slavonic texts. Overall, the structured
testing confirms that the tool is already capable of providing semantically coherent
results, useful for philological and theological inquiry, even in the presence of
complex linguistic variants. Its strength lies in the combination of broad retrieval
coverage and conceptual recognition, while the observed limitations offer pathways
for further development rather than indicating structural flaws. The system thus presents
itself as a promising platform that can significantly contribute to research on premodern
Slavic texts, provided it is supported by a clearly structured user guide tailored
to the needs of specialist users.
The issue raised in the test by the response“The tool gave plenty of answers but some of them seemed not related to the original
quotation (И въ Д
ꙋ
ха Свѧтаго, Господа истиннагѡ и животворѧщаго, иже от Отца исходѧщаго. Иже со Отцемъ
и съ Сыномъ спокланѧема и сславима, глаголавшаго пророки.И въ Духа Святаго Господа
истиннаго и животворящаго, иже от Отца изходящаго. иже со Отцемъ и съ Сыномъ съ покланяема
и съ славима, глаголавшаго пророки.)” is of our particular interest, as the evaluations were conducted independently and
at different times by the author of the this paper and by external academic participants.
This convergence reinforces the necessity, already highlighted above, of complementing
the tool with a methodological vademecum to guide its effective use. In this case,
it remains unclear what similarity score was applied by the user during testing, and
a notable methodological discrepancy emerges: whereas participants were instructed
to assess semantic relevance across the top ten retrieved passages, the author’s own
analysis was limited to the first three results. This methodological divergence was
intentional, aimed at generating differentiated insights that reflect multiple and
autonomous modes of interaction with the tool.
| Comments and Feedback |
Analysis |
|
“The tool gave plenty of answers but some of them were too far from the intended sense
of the query”
“In general, the model suggests close, semantically related contexts”
“They were not errors per se, but some inconsistencies in the connection between query
and retrieved text”
|
All of these responses, related to the results obtained from the initial query, highlight
a limitation that is still inherent in the tool and will need to be addressed in future
work. Beyond the need to train and fine-tune a model specifically for Old Church Slavonic,
what appears to be the main reason why the results are not always semantically consistent
with the initial query—or only partially so—is the amount of data on which the model
is trained. LLM typically rely on substantially larger corpora; therefore, expanding
and improving the dataset will be a necessary prerequisite for achieving greater accuracy
in the results. |
| “When searching the text from manuscript corpora, the query failed entirely” |
The issue identified in this case—namely, that when searching texts from manuscript
corpora the query failed entirely—highlights a limitation that is related to, yet
distinct from, those discussed previously. While data scarcity is certainly a relevant
factor, this problem also points to challenges associated with OCR and HTR processes,
as noted in earlier sections. In addition, it raises the issue of language standardization
during OCR processing, which does not allow for the preservation of linguistic features
that vary according to historical period and geographical origin. Future work will
aim to develop a dataset comprising texts derived from OCR and HTR processes applied
to manuscript sources. |
| “The blocks of text are too vague to make any fine-tuned assessment” |
This issue is identified in relation to the ability to detect errors or inconsistencies
in the results suggested by the model. To address this problem, efforts have been
made to improve the clarity of the interface, thereby making it easier for users to
access a larger portion of text through the “more details” label. In this context,
the sentences identified by the model as semantically related are highlighted in yellow,
and users can gain a clearer understanding of the surrounding context as well as access
the full text by following the corresponding link provided within the “more details”
window. |
|
“Very well”
Not very well
|
The issues previously discussed are clearly reflected in these two assessments, both
concerning the model’s ability to capture the contextual meaning of sentences in (Old)
Church Slavonic. This interpretation is further corroborated by the following response,
which, like the other two, refers to the aforementioned question: “I honestly think that there's a long way to go to add corpora (of course this takes
a lot of work and time), but the premises are good.” |
|
“This model, to my knowledge, is the first to find semantically related passages in
OCS”
“I think it can do it the future, with further work. Then, it would definitely do
it. It would be super useful for research”
“I am not sure, because I have no prior experience with this type of tool”
|
The proposed functionalities are considered innovative despite the limitations highlighted
both in the previous comments and throughout this paper. These findings indicate that
the perception of innovativeness is particularly strong among users familiar with
Slavic studies and computational tools, whereas it remains less defined in the absence
of comparative experience.
From the perspective of research advancement in the field of NLP and (Old) Church
Slavonic, the results can be regarded as positive, according to the opinions collected.
It is hoped that future work will address the identified issues, both in relation
to the functioning of the tool and to the application of NLP techniques to Old Church
Slavonic texts.
|
| “A brief vademecum should be added to show how queries must be formulated” |
This highlights a concrete need for user orientation: the formulation of queries,
in terms of morphosyntactic structure, lemma selection, and management of textual
variants, has a direct impact on the quality of the results. The presence of a vademecum,
even a basic one, could significantly enhance the user experience by making interaction
with the system more accessible, effective, and replicable. It is also thanks to suggestions
such as these that a user manual has been included in the Support section of HORTUS, the website where the results of all the project’s work packages are published.
|
6. Conclusions
The development of a semantic tool for Old Church Slavonic (OCS) and Church Slavonic
texts, presented in this study, took place within a research context marked by significant
methodological and technical challenges. The main difficulties concern the a) scarcity
of digitalized linguistic resources available in plain text; b) the fragmentation
of existing resources across multiple online repositories; c) the fact that texts
in these repositories are not always encoded using Unicode-compliant characters; d)
the absence of shared normalization standards, and the intrinsic complexity of the
Slavonic manuscript tradition, often characterized by fragmentary documentation and
insufficient metadata. Moreover, the particularities of the scripts, orthographic
features, and diacritical signs, though difficult to preserve in standard NLP tools,
are essential for conducting studies on historical, geographical, and linguistic variation.
Such variation is foundational not only for Slavic philological research but also
for broader investigations into the history of these regions and the cultural influences
and contaminations that shaped them.
One of the most important takeaways from this overview is that the issue of text normalization
remains unsolved. There is an urgent need to develop analytical methodologies capable
of processing non-normalized texts. Such approaches are crucial in preserving the
orthographic and stylistic idiosyncrasies of the language, which are essential not
only for diachronic linguistic research, but also for rigorous philological analysis
that can engage meaningfully with the theological, cultural, and semantic dimensions
of the texts.
In addition, the literature review clearly shows that, although transformer-based
language models have achieved strong performance in modern contexts and, to some extent,
in high-resource historical languages, they remain insufficiently adapted to low-resources
corpora marked by high diachronic, orthographic, and dialectal variation, such as
Old Church Slavonic and Church Slavonic. The solutions proposed thus far have predominantly
relied on hybrid (rule-based and statistical) approaches, yielding promising results
in part-of-speech tagging and morphological analysis, yet still falling short in deep
semantic modeling and diachronic variation. As noted, current research efforts in
the field have primarily focused on two key objectives: a) dating manuscripts and
determining their geographic provenance, and b) identifying biblical citations and
allusions within OCS texts.
In this context, the tool introduced in our study represents an original and methodologically
grounded contribution to computational research on (Old) Church Slavonic texts. The
platform enables semantic queries that go beyond literal matching, identifying conceptually
related expressions even when they exhibit morphosyntactic variation or reformulation.
The research has focused on semantic similarity analysis using the Nicene-Constantinopolitan
Creed as a case study. Due to its brevity and doctrinal centrality, the Creed functions
as a core liturgical formula with high doctrinal content, providing an ideal reference
point for analyzing both its source culture and patterns of reception across regions
and centuries.
The results, particularly in comparing different versions of the Nicene-Constantinopolitan
Creed, demonstrate the tool’s capacity to support lexical change analysis over time,
offering results that are both linguistically and semantically significant.
The adoption of a semantic-oriented embedding model (Jina Embeddings V3) has proven
to be a sound choice for the liturgical-Slavonic domain, where vocabulary is highly
connotative and theologically dense. The system has shown its ability to return relevant
outputs even in the absence of exact textual matches, such as in the replacement of
“нѣсть несть кѡнца конца” with “не бꙋдетъ кѡнца не будет конца,” or the disappearance
of the adjective “истиннагѡистиннаго” (“true”) referring to the Holy Spirit in pre-Nikonian
reform texts.
Structured testing conducted with experts in Slavic studies and digital humanities
confirmed the tool’s usefulness, while also highlighting areas for improvement, particularly
regarding the conceptual coherence of retrieved results and the system’s interpretability
when confronted with non-standard query formulations. These observations underscore
the necessity of supplementing the platform with a methodological guide to assist
users in query construction and in critically interpreting the system’s outputs.
Overall, the tool emerges as an innovative resource for semantic inquiry into (Old)
Church Slavonic texts, capable of offering new perspectives in theological, historical,
and linguistic research. It not only facilitates information retrieval but also serves
as a conceptual exploration instrument, enabling the tracing of lexical and semantic
variants across time. This approach lays the groundwork for deeper integration between
traditional philology and semantic technologies in the study of premodern religious
texts.
The development of our tool has confirmed the need to address the limitations outlined
above, particularly the ongoing data scarcity, which remains a major bottleneck. It
has also highlighted the importance of improving OCR and HTR methodologies to ensure
the acquisition of reliable digital resources. Although, as noted in Pedrazzini’s
2020 study, computational methods for early Slavic texts are making steady progress,
particularly in relation to the digitization of primary sources
[35] (Rabus and Petrov, 2023; Lendvai et al., 2024), the use of HTR and OCR techniques
for the digitization of Old Church Slavonic and Church Slavonic texts remains an unresolved
challenge. The contributions of these scholars represent a critical foundation for
future work, but additional resources are still required to optimize model performance
in Transkribus and to advance alternative frameworks such as eScriptorium. Improvements
in this area will be essential for increasing the availability of high-quality textual
data, thereby enabling the eventual training of LLMs for historical Slavic languages.
A further significant challenge was the widespread use of PUA (Private Use Area) characters.
These characters frequently manifested in the dataset as what is colloquially referred
to as “tofu”, placeholder glyphs (e.g., boxes or question marks) that indicate missing
font support.
Accordingly, future development phases of our tool will also require the integration
of extended PUA-Unicode mappings to ensure consistent and accurate frontend rendering.
Although this issue does not affect the tool’s semantic retrieval capabilities, it
can nonetheless lead to confusion for users and compromise the overall user experience.
Acknowledgments
This paper is the outcome of a collaborative work developed within WP4 of the ITSERR
project, entitled DaMSym - Data Mining: the Nicene-Constantinopolitan Symbolum, and
focused on the specific case study of Old Church Slavonic and Church Slavonic. In
particular, sections 1 and 6 were jointly authored by both contributors; sections
2, 3, and 5 were written by Marianna Napolitano; and section 4 was authored by Giovanni
Puccetti.
This work was supported by the PNRR (National Recovery and Resilience Plan) project
Italian Strengthening of ESFRI RI Resilience (ITSERR) founded by the European Union—NextGenerationEU
(CUP:B53C22001770006).
Works Cited
Aksakov 2011 Aksakov, K.S. (2011) Opyt russkoi grammatiki: Sravnitelnyi vzgliad: Indoevropeiskie i slavianskie iazyki (reprintnoe izd.; Moskva: URSS/Librokom), 303 s. (Lingvisticheskoe nasledieXIX veka).
Andreev 2015 Andreev, A., Shardt. Y., and Simmons, N. (2015) “Church Slavonic typography in unicode”, Unicode Technical Note pp. 41, 1–97.
Artetxe and Schwenk 2019 Artetxe, M. and Schwenk. H. (2019) “Massively multilingual sentence embeddings for zero-shot cross-lingual transfer and
beyond”, Transactions of the Association for Computational Linguistics 7, pp. 597–610.
Baranov et al. 2003 Baranov, V., Birnbaum, D., Cleminson, R., Rabus, A. and Miklas, H. (2003) ‘Proposal
for a Unified Encoding of Early Cyrillic Glyphs in the Unicode Private Use Area’,
E-Scripta 3, pp. 25–52.
Baranov et al. 2007 Baranov, V., Mironov, A., Lapin, A., Mel’nikova, I., Sokolova, A., and Korepanova,
E., (2007) “Avtomaticheskii morfologicheskii analizator drevnerusskogo iazyka: lingvisticheskie
i tekhnologicheskie resheniia”, in Proceedings of the 10th Anniversary International Conference “EVA 2007 Moskva”, Moscow, 2007) pp. 61–68.
Baranov et al. 2010 Baranov, V., Birnbaum, D. J., Cleminson, R., Miklas, H., and Rabus, A., (2010)
“Proposal for a unified encoding of Early Cyrillic glyphs in the Unicode Private Use
Area”, Scripta & e‑Scripta 8–9, pp. 9–26.
Berdichevskii, Eckhoff, and Gavrilova 2016 Berdichevskii , A., Eckhoff, H. M., and Gavrilova, T. (2016) “The beginning of a beautiful friendship: Rule-based and statistical analysis of Old
Russian”, in Computational Linguistics and Intellectual Technologies: Papers from the Annual Conference
Dialogue 2016 (Moscow: RSUH), pp. 9–16.
Berti et al. 2016 Berti, M., Blackwell, C., Daniels, M., Strickland, S., and Vincent-Dobbins, K.,
(2016) “Documenting Homeric text-reuse in the deipnosophistae of Athenaeus of Naucratis”, Bulletin of the Institute of Classical Studies 59, pp. 121–139.
Biagetti, Zanchi, and Luraghi 2021a Biagetti, E., Zanchi, C., and Luraghi, S. (eds.). (2021) “Building new resources for historical linguistics (Prima edizione)”. Pavia University Press.
Biagetti, Zanchi, and Luraghi 2021b Biagetti, E., Zanchi, C., and Luraghi, S. (2021) “Introduction: The value of digital resources for historical linguistics”, in Biagetti, E., Zanchi, C., and Luraghi, S. (eds) Building New Resources for Historical Linguistics. Pavia University Press, pp. 1–20.
Birnbaum 1996 Birnbaum, D. J. (1996) “Standardizing characters, glyphs, and SGML entities for encoding early Cyrillic writing”, Computer Standards and Interfaces 18, pp. 201–252.
Brants 2000 Brants, T. (2000) “TnT – A statistical part-of-speech tagger”, in Proceedings of the Sixth Applied Natural Language Processing Conference. Association for Computational Linguistics, pp. 224–231.
De Marneffe et al. 2021 De Marneffe, M.-C., Manning, C.D., Nivre, J., and Zeman, D. (2021) “Universal Dependencies”, Computational Linguistics 47, pp. 1–54.
Deshpande et al. 2023 Deshpande, A., Jimenez, C., Chen, H., Murahari, V., Graf, V., Rajpurohit, T., Kalyan,
A., Chen, D., and Narasimhan, K. (2023) “C-STS: Conditional semantic textual similarity”, in Bouamor, H., Pino, J., and Bali, K. (eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, pp. 5669–5690.
Devlin 2019 Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019) “BERT: Pre-training of deep bidirectional transformers for language understanding”, in Burstein, J., Doran, C., and Solorio, T. (eds.) Proceedings of the 2019 Conference of the North American Chapter of the Association
for Computational Linguistics: Human Language Technologies. 1: Long and Short Papers.Association for Computational Linguistics, pp. 4171–4186.
Dorkin and Sirts 2024 Dorkin, A. and Sirts, K. (2024) “TartuNLP @ SIGTYP 2024 Shared Task: Adapting XLM-RoBERTa for ancient and historical
languages”, in Hahn, M., Sorokin, A., Kumar, R., Shcherbakov, A., Otmakhova, Y., Yang, J., Serikov,
O., Rani, P., Ponti, E.M., Muradoğlu, S., Gao, R., Cotterell, R., and Vylomova, E.
(eds.) Proceedings of the 6th Workshop on Research in Computational Linguistic Typology and
Multilingual NLP. Association for Computational Linguistics, pp. 120–130.
Eckhoff and Haug 2021 Eckhoff, H.M. and Haug, D.T.T. (2021) “Annotation schemes, tools and data in the PROIEL Treebank family”, in Biagetti, E., Zanchi, C., and Luraghi, S. (eds.) Building New Resources for Historical Linguistics. Pavia University Press, pp. 21–30.
Eckhoff et al. 2018 Eckhoff, H.M., Bech, K., Bouma, G., Eide, K., Haug, D., Haugen, O.E., and Jøhndal,
M. (2018) “The PROIEL treebank family: a standard for early attestations of Indo-European languages”, Language Resources and Evaluation 52 (1), pp. 29–65.
Feliksov 2018 Feliksov, S.V. (2018) “Semantic aspect of the linguistic description of lexicon of orthodox dogma in church
Slavonic language”, RUDN Journal of Language Studies, Semiotics and Semantics 9(2), pp. 335–350.
Fernández-González and Gómez-Rodríguez 2019 Fernández-González, D. and Gómez-Rodríguez, C. (2019) “Faster shift-reduce constituent parsing with a non-binary, bottom-up strategy”, Artificial Intelligence 275, pp. 559–574.
Ferro, Salmon, and Ziffer 2018 Ferro, M.C., Salmon, L., and Ziffer, G. (eds.) (2018) Contributi italiani al XVI Congresso Internazionale degli Slavisti: Belgrado 20–27
agosto 2018, 1st ed.; 40. Firenze University Press.
Garzaniti 2019 Garzaniti, M. (2019) Gli Slavi: storia, culture e lingue dalle origini ai nostri
giorni, 2nd ed., 207 of Manuali universitari. Lingue e letterature straniere (Rome:
Carocci).
Janda and Exkhoff 2016 Janda, L. and Eckhoff, H. M. (2016) “Grammatical profiles and aspect in old church Slavonic”, Transactions of the Philological Society 114, pp. 233–255.
Kamchatnov 1998 Kamchatnov, A.M. (1998) Istoriia i germenevtika slavianskoi Biblii. Nauka.
Kamchatnov and Nikolina 2008 Kamchatnov, A.M. and Nikolina, N.A. (2008) Vvdenie v jazykoznanie: učebnoe posobie, 7th ed. Flinta.
Kempgen 2008 Kempgen, K. (2008) “Unicode 5.1, old church Slavonic, remaining problems – and solutions, including OpenType
features”, in Slovo: Towards a digital library of south Slavic manuscripts, Proceedings of the International Conference, 21–26 February 2008, Sofia, Bulgaria (Sofia), pp. 200–219.
Kostromin 2012 Kostromin, K. (2012) “Istoriia slavianskogo teksta Simvola very cherez prizmu istorii raskola XVII v”, Khristianskoe chtenie 3, pp. 32-65.
Lendvai et al. 2023 Lendvai, P., Reichel, U., Jouravel, A., Rabus, A., and Renje, E. (2023) “Domain-Adapting BERT for attributing manuscript, century and region in pre-modern
Slavic texts”, in Proceedings of the 4th Workshop on Computational Approaches to Historical Language
Change. Association for Computational Linguistics, pp. 15–21.
Lendvai et al. 2024 Lendvai, P., Van Gompel, M., Jouravel, A., Renje, E., Reichel, U., Rabus, A., and
Arnold, E. (2024) “ A workflow for HTR-Postprocessing, labeling and classifying diachronic and regional
variation in pre-modern Slavic texts”, in Calzolari, N., Kan, M.-Y., Hoste, V., Lenci, A., Sakti, S., and Xue, N. (eds.)
Proceedings of the 2024 Joint International Conference on Computational Linguistics,
Language Resources and Evaluation (LREC-COLING 2024). ELRA and ICCL, pp. 2039–2048.
Lendvai et al. 2025 Lendvai, P., Reichel, U., Jouravel, A., Rabus, A., and Renje, E. (2025) “Retrieval of parallelizable texts across church Slavic variants”, in Scherrer, Y., Jauhiainen, T., Ljubešić, N., Nakov, P., Tiedemann, J., and Zampieri,
M. (eds.) Proceedings of the 12th Workshop on NLP for Similar Languages, Varieties and Dialects. Association for Computational Linguistics, pp. 105–114.
Lewis et al. 2020 Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler,
H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., and Kiela, D. (2020) “Retrieval‑augmented generation for knowledge‑intensive NLP tasks”, Advances in Neural Information Processing Systems 33, pp. 9459–9474.
Meyendorff1991 Meyendorff, P. (1991) Russia, ritual, and reform: The liturgical reforms of Nikon in the 17th century. St Vladimir’s Seminary Press.
Meyer 2011 Meyer, R. (2011) “New wine in old wineskins? — Tagging Old Russian via annotation projection from modern
translations”, Russian Linguistics 35 (2), pp. 267–281.
Napolitano 2025 Napolitano, M. (2025) “La riforma liturgica del patriarca Nikon (1653–1656): la riformulazione del Credo
in russo”, in C. Bianchi/A. Melloni/M. Proietti (ed.) Il concilio e il Credo, 325–2025. Storia e trasmissione dei simboli di Nicea e di
Costantinopoli. EDB, pp. 309–323.
Papineni 2001 Papineni, K. (2001) ‘Why Inverse Document Frequency?’, Proceedings of the Second Meeting of the North American Chapter of the Association
for Computational Linguistics (NAACL), pp. 25–32.
Pedrazzini 2020 Pedrazzini, N. (2020) “Exploiting cross-dialectal gold syntax for low-resource historical languages: Towards
a generic parser for pre-modern Slavic”, arXiv preprint. arXiv:2011.06467.
Postovalova 2022 Postovalova, V.I (2022) Nauka o jazyke v svete ideala cel’nogo znanija: V poiskach integral’nych paradigm. LENAND.
Qi et al. 2020 Qi, P., Zhang, Y., Zhang, Y., Bolton, J., and Manning, C.D. (2020) “Stanza: A Python natural language processing toolkit for many human languages”, in Celikyilmaz, A. and Wen, T.-H. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics:
System Demonstrations. Association for Computational Linguistics, pp. 101–108.
Rabus 2019 Rabus, A. (2019)
“Recognizing handwritten text in Slavic manuscripts: A neural-network approach using
Transkribus”, unpublished paper. Available at:
https://www.academia.edu/38835297. Accessed 20 July 2025.
Rabus and Petrov 2023 Rabus, A. and Petrov, I. N. (2023) “Linguistic analysis of church Slavonic documents: A mixed-methods approach”, Scando-Slavica 69(1), pp. 25–38.
Reimers and Gurevych 2019 Reimers, N. and Gurevych, I. (2019) “Sentence-BERT: Sentence embeddings using Siamese BERT-Networks”, in Inui, K., Jiang, J., Ng, V., and Wan, X. (eds.) Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing
and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, pp. 3982–3992.
Ruskov et al. 2025 Ruskov, T., Mikulka, T., Podtergera, I., Gavrilkov, M., and Thompson, W. (2025) “Quotes at the fingertips: The BogoSlov Project’s combined approach”, in Proceedings of the 21st Conference on Information and Research Science Connecting
to Digital and Library Science (IRCDL 2025), pp. 393–407.
Scherrer, Rabus, and Mocken n.d. Scherrer, Y., Rabus, A., and Mocken, S. (n.d.) “New developments in tagging premodern orthodox Slavic texts”, Scripta & e-Scripta 18, pp. 9–33.
Shakhov 1997 Shakhov, M.O. (1997) Filosofskie aspekty staroveriia. Tretii Rim, pp. 45–47.
Sidash 2013 Sidash, T. (2013) Skrizhal: Akty soborov 1654, 1655, 1656 godov. Svoe izdatelstvo.
Sturua et al. 2024 Sturua, S., Mohr, I., Akram, M.K., Günther, M., Wang, B., Krimmel, M., Wang, F.,
Mastrapas, G., Koukounas, A., Wang, N., and Xiao, H. (2024) “jina-embeddings-v3: Multilingual Embeddings With Task LoRA”, arXiv preprint. arXiv: 2409.10173.
Tomelleri 2022 Tomelleri, V.S. (2022) “When church Slavonic meets Latin: Tradition vs. innovation”, in Diachronic Slavonic Syntax. De Gruyter Mouton, pp. 201–232.
Vaswani et al. 2017 Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser,
Ł., and Polosukhin, I. (2017) “Attention is all you need”, in Advances in Neural Information Processing Systems 30, pp. 5998–6008.